There are few things worse than jet-lag and awaking at 3 AM in San Francisco after a few hours of sleep. One of them is to awake to see Trump won the elections.
I’m Spanish so I lived the winning of the right-wing political ideology at several levels: our own poll results, the Brexit and now this.
I’m reading Twitter, a convenient social network to express opinion and receive proper confirmation of followers. Given my nature and the people I follow, you can guess which kind of comments I’m reading. What I read is mainly frustration, hate and blaming.
Blaming against the other America, the America that let Trump win. But here is the truth, there is no other America. Since the very first moment after the result of the polls, you’re in together for the next 4 years and you’re all responsible for the future of your country.
To blame the other America won’t change the facts. What happened yesterday is history. You can learn from it but you can not change it. Fortunately, you can start worrying about what you will do next.
But blaming will create a false difference between blamers and the people who is blamed. A sense of being questioned and attacked. There will be people taking advantage of it. Those are the enemy. Don’t let them recruit among angry people.
I don’t know, Americans, if the path you are walking will be violent or not but you will need allies, not a fictitious separation.
Go, cry and rant today if you need it but stop blaming your own nation and start making alliances. You will need them.
Chris Wilson offered an excellent introduction to Progressive Web Applications, «Progressive Web Apps are the new AJAX» at View Source Berlin. Chris showed a slide where, after applying PWA principles to a web site, conversions increased even on iOS (by a not negligible 82%), a platform where neither Service Workers, Web Push or Application Manifest are supported.
During his talk, Chris put the emphasis on user experience, saying PWAs are all about UX, not technologies and this is precisely one of the most fascinating things PWAs are doing, changing the developer mindset about prioritizing UX.
In his post, Alex highlights the importance of meeting some baseline criteria for your app to become an A+ progressive web app and do Chrome show the “Add to Home Screen” dialog. As you probably know, these constraints require the usage of certain technologies in an specific way: the developer must serve the page on HTTPS, use a Service Worker and link a manifest providing a minimal set of keys and specific values. All three are necessary (although not sufficient) for a web app to be reliable, to offer an offline experience and to be integrated with the mobile OS. Ultimately, all three characteristics contribute to a better user experience.
Reliability aside, like it or not, offline experience and platform integration can be achieved by using non-PWA-related technologies such as App Cache (ugly but still a standard and a cross platform one at that) and OS-proprietary meta-tags. Fortunately, high performance best practices, techniques and patterns are vendor-independent.
Although I can see the good intention behind technology requirements –the dialog is acting as a reward for developers minding UX–, in my opinion, Chrome is going too far not only guessing when users are deeply engaged with a web app, but determining what specific kind of web apps users can engage with. Notice that only if technical requirements are met, user engagement heuristics come into play. User engagement is measured but performance isn’t, performance is expected as a result of using specific technology.
Compare with app stores. We rant at Apple or Google for deciding which kind of content is appropriate and what is not but at least, once developers observe content policies and the app gets published, the install button is there for anyone finding their application. Targeting the Web now means that in Chrome, even if the developers figured out how to leverage user engagement, the users will never see the install button unless the app meets the technical constraints.
Don’t misunderstand me. I really think that Home Screen launchers / shortcuts / bookmarks / whatever are a good idea but if browsers are going to demand UX excellence from developers, they should do by measuring performance during user interaction, not by tying development to a trendy technology stack. Regardless of impositions, the ultimate indicator about engagement will come from the user. Browsers should focus on leveraging UX for users’ interests and not deciding what users should engage with.
I would love to see Mozilla, in its role of user advocate, taking a strong position on this matter by providing its own user-centric alternative.
Recently, I exchanged some e-mails with Anne van Kesteren about security models for the Web. He wrote his thoughts down in an interesting post on his blog titled Web Computing. This is sort of a reply to that post with my own thoughts.
Today, 10,000 days after, the first published Web is still working (congratulations! ^^). 10,000 days ago, JavaScript did not even exist but now we are about to welcome ES6 and the Web has more the 12,000 APIs.
Latecomers Service Workers, Push and Sync APIs have revitalized web sites to compete with their native counterparts but if we want to leverage the true potential of the Web we should increase the number of powerful APIs to stand at the same level of native platforms. But powerful APIs imply security risks.
To encourage the proposal and implementation of these new future APIs, an effective, non-exploitable revocation scheme is needed.
In the same way we can detect and block certain deceptive sites, we could extend this idea to code analysis. Relying on the same arguments supporting the success of open source communities, perhaps a decentralized network of security reviews and reviewers is doable.
I imagine a similar warning for web properties proven to be harmful.
This decentralized database (probably persisted by user agents) would declare the safeness of a web property based on the presumption of innocence which means, in roughly statistical terms, that our hypothesis should be «the web property is evil» and then try to find strong evidence to beat the null hypothesis «the web property is not evil».
Regardless the methodology chosen there will be two main categories: we have not enough evidence for a web to be declared harmful (or we are completely sure it is safe) and we have strong evidence for a web to be considered harmful. We should take some action in the latter and not alert the user in the former but, what should we actually do? Not sure yet, honestly.
For instance, in case of strong evidence, should the user agent prevent the user from accessing the web site? Or should it automatically revoke some permissions and query the user again? Could the user decide to ignore the warnings?
There are more gaps to fill starting by providing a formal definition of harmful. I.e., what does harmful mean in our context? Should a deceptive site be considered harmful from this proposal’s point of view? Consider a phishing site with a couple of input tags for faking Gmail login page with a simple POST form and no JavaScript at all… In my opinion, we should not focus on site’s honesty but in API abuse. We already have mechanisms for warning about deception and if you want to judge web site reputation, consider alternatives such as My Web Of Trust.
In his response, Anne highlighted the importance of not falling in the CA trap «because that means it’s again the browsers that delegate trust to third parties and hope those third parties are not evil«.
OpenPGP has the concept of ring (or web) of trust for a decentralized way to grant trustworthiness. What if instead of granting trustworthiness, UAs provide a similar structure to revoke it? Kind of issuing a mistrust certificate.
And finally, there is the inevitable problem related to auditing a web site. The browser could perform some static analysis and provide a per-spec first judgement but what would happen after? Can we provide some kind of platform to effectively allow decentralized reviews by users?
In my ideal world, I imagine a community of web experts providing evidences of API abuse, selecting a fragment of code and explaining why that snippet constitutes an instance of misuse or can be considered harmful, other users can see and validate the evidence. Providing this evidence would be a source of credit and recognition to the same extent as contributing to Open Source projects.
Another bunch of uncomfortable questions arise here, though. What if the code is obfuscated or simply minified? How does the browser track web site versions? Should the opinions of reviewers be weighted? By which criteria?
Well, that’s the kind of debate I want to start. Thoughts?
Now I’m talking publicly about progressive web apps and the future of Web development and the Internet, I’ve been asked a lot for my opinion about instant apps and, before instant apps, about why Google was trying to close the gap between the Web and native platforms, i.e. Android.
Actually, I don’t really know but despite the strategy would seem contradictory, after Google I/O it seems obvious to me: Google is running an experiment about switching its distribution platform. to bring more users to the search engine.
Why? Well, it makes sense that there should be a correlation between the time a user spends on Google search engine and the amount of money Google earns. So here is my assumption: given the marketplace is free from ads and most of the content is free, browsing the marketplace is not profitable or, at least, not as profitable as the Google search engine.
But we like applications, and to use applications implies some behaviour patterns, the result of all these years of mobile education. So, in order to make Web applications more appealing (and so, to increase the time a user spent in the search engine) why not to add native-application characteristics to Web applications?
In the other hand, it is Android. Another common question these days is: will we, Android developers, loose our jobs in the future? As if some of Android developers would feel threatened by progressive web apps in some way.
Well, honestly, I think no, at least in the near and mid time scenarios and Google has provided some extra warranties to make Android last for even more time. With Instant Apps, Google is closing the gap from the other end, it’s bringing to Apps what we like most from the Web: immediacy (no market, no download, no installation) and URLs so now we can search for Apps in Google engine. And that’s the point! No market, more time spent in Google search engine.
And why to bet for two approaches instead of one? Because it brings more users to the search engine and… they can (in terms of costs). If both initiatives succeed, both developer communities will be happy and users will spend their time into the most profitable distribution platform they can use: the Internet. Everybody win and the world is a wonderful place… for somebody. 😉
And that’s all folks! Notice that I could be totally wrong since all this is based on the premise that Google earns more money from the engine than from the market but there is some data to support my assumption out there (google it!) and, in the end, this is only speculation.
EDIT: I changed the nature of the experiment as it was not accurate enough. It is more clear now.
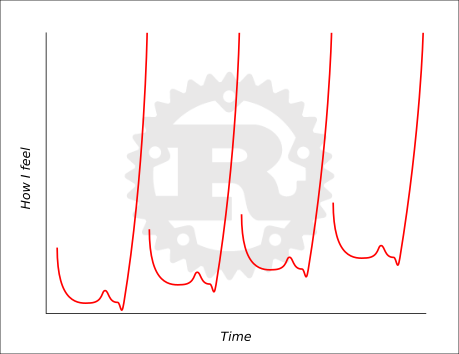
I finished my first patch with Rust! \0/ I don’t feel specially proud of it but I’m happy because it is my first contribution to a real project. It has a lot of flaws and technical debt but this is only a prototype and a sandbox for Rust exploration.
In short, the experience is exciting followed by a deep sense of uncertainty, then frustration with a small pinch of enlightenment just to be followed by a rewarding sensation at the end.
You can see 4 cycles here, each with stages of excitement, uncertainty, frustration, enlightenment and finally, the step upwards depicts the reward.
It is exciting because it introduces a lot of new syntax (for me, a new, cool and different syntax compared with JavaScript or Python) with lots of annotations and symbols everywhere. I feel like engineering something precious, delicate but at the same time I feel confident on its robustness cause I’m adding tons of metadata for the compiler. Furthermore, I’ve followed some tutorials and the compiler errors seems very clear, they are even helping and advising me. I’ve read about borrowing, lifetimes and mutability but in the tutorials those never seemed to be a problem.
Then it comes uncertainty. I know what to do but I don’t know how to write it. When learning a new language I lack from two things: a deep knowledge of the API and idioms. And idioms are the most important feature of a language because in the long term you prefer to read idioms. These are patterns that immediate associate with well know and repetitive behaviors. For instance. These three snippets do the same:
My first approach was option 2. It is very similar to C or JavaScript. But then I remember the people that writes Python as it was C. I hate them. Probably I hate you. Naaaah… just joking. But as a Python and JavaScript teacher I try to explain why idioms matter. Then I turned to option 1 and only for this post and after investigating the Option API, I realize about option 3. Currently, I don’t know what is more idiomatic but I would bet for the last option.
Once you are happy with your third refactor, you finally launch the tests and they fail… No, wait! That happens, but much later. First it comes the compiler, the type reasoner and the borrow checker. Let me illustrate the problem with an example. Suppose you want to test the former option 2: in play Rust… (no! no the f*ck*ng game, I did not play it yet but I already hate it), this play Rust(-lang). You want to enclose it in a function, then call it. No run, just see if it compiles.
<anon>:1:16: 1:22 error: wrong number of type arguments: expected 1, found 0 [E0243]
<anon>:1 fn test(maybe: Option) -> Result {
^~~~~~
<anon>:1:16: 1:22 help: see the detailed explanation for E0243
<anon>:1:27: 1:33 error: wrong number of type arguments: expected 2, found 0 [E0243]
<anon>:1 fn test(maybe: Option) -> Result {
^~~~~~
<anon>:1:27: 1:33 help: see the detailed explanation for E0243error: aborting due to 2 previous errors
playpen: application terminated with error code 101
Read the errors. Try again… Seriously, read the errors. You’ll discover that they make a lot of sense, Option must be an Option of some type so be it Result (but Result needs two types, one for valid values and other for errors).
<anon>:3:20: 3:32 error: mismatched types:
expected `collections::string::String`,
found `&'static str`
(expected struct `collections::string::String`,
found &-ptr) [E0308]
<anon>:3 return Err("Some error");
^~~~~~~~~~~~
<anon>:3:20: 3:32 help: see the detailed explanation for E0308error: aborting due to previous error
playpen: application terminated with error code 101
Well, now it turns out string literals in Rust are not String but &’static str. What does it mean? That means reading the docs again. Fortunately the compiler gives you enough info to solve the errors. Uncertainty again, I could convert this &str to a real String (expected in the errors) but I’m happy with a Result of type &str (found in the errors). So, I modify the signature of the function and…
<anon>:1:43: 1:50 error: missing lifetime specifier [E0106]
<anon>:1 fn test<T>(maybe: Option<T>) -> Result<T, &String> {
^~~~~~~
<anon>:1:43: 1:50 help: see the detailed explanation for E0106
<anon>:1:43: 1:50 help: this function's return type contains a borrowed value with an elided lifetime, but the lifetime cannot be derived from the arguments
<anon>:1:43: 1:50 help: consider giving it an explicit bounded or 'static lifetimeerror: aborting due to previous error
playpen: application terminated with error code 101
What the hell!? Ok, now I need a lifetime specifier. Lifetime specifier…, lifetime specifier… where are those bl**d* specifiers!? Oh, here! Well, you get the idea. This time the problem was I missed a lifetime specifier. As Rust needs to know how much this reference is going to live to check if the returning value lives long enough to not leave you with dangling pointers. Do you understand? Well, probably not, but I do (or at least, I did) which leads me to the next point: enlightenment!
Trying to figure out which kind of lifetime I want to assign for the returning structure, I though: I want these errors to be immortal strings (which translates into ‘static lifetimes) in order to not produce new strings and reuse them. Suddenly, for a fraction of time, I understand everything: lifetimes, specifiers, elision and immortality (well… staticness) and then… it’s gone. This is what I call enlightenment. No more than a fraction of second you understand what are you doing in this new context which is Rust.
Similar to what astronauts call overview effect, this is what you experiment with Rust from time to time. When you are not fearing about the huge fall you have below.
Paradoxically, If I would read the errors from the second try more carefully, I should have read that the expected type was &’static str preventing me from the third try but at the same time impeding this moment of truth to happen.
The remaining sensation is rewarding. Bit after bit, I’ll adapt my mind to these new memory and execution models. Reading articles, answers and books I will learn more knowledge about the internals of the data and execution models for Rust at the same time I will borrow some idioms.
Of course, once the code compiles, test are failing and the cycle repeats again. Most hard part is frustration and uncertainty (what else?) but it is completely normal. You can think of yourself as some kind of ninja or choosen-one inside your comfort zone. Modesty aside, I think this of myself when working on JavaScript or Python but when you are in the wild, failure is something normal. During these days, I even realized that my way of debugging / developing with dynamic languages is not suitable for this strongly typed language! But if it was easy, where would be the fun?
Look at those bullet holes on Neo shirt: failure is natural before enlightenment. Mr Anderson learned it the hard way.
I never though seriously about IoT until Mozilla announcement about Firefox OS pivoting to Connected Devices. What caught my attention was this new team name: connected devices. What is a connected device? Do I have connected devices? Do I ever missed to be able of controlling them from a remote place? Those were the questions I was asking to myself and it turned out that I already knew the answer because I had connected devices just there in my living room (video console, TV and home-cinema) and yes, I wanted to control them remotely.
These days I was thinking about the not-so-far future with most of my domestic electronics connected, generating data, signals going and coming through the Internet and devices accepting remote control from anyplace where Internet works. I was wondering how will be living those days. In particular, given my professional relationship with Mozilla and my personal experience with the browser Firefox, I was wondering how the browsers will evolve to be part of that future?
The browser is a wonderful piece of software that evolved from nothing more than an hypertext render to what nowadays is known as the user agent (to be precise, the browser is a kind of user agent). A user agent such as modern browsers not only displays the Web as it’s expected but implements a set of measures and policies to keep the user, their privacy and their data safe. Web companies, foundations and institutions have agreed on those policies and all the browsers implement them. This way you can change from one browser to another without compromising your security or privacy.
Information about the WordPress admin site.
This works as the consumer point of view. The user agent defends you from the Internet. It exposes a safe portion of the Web.
But what we miss from time to time is the other side of the browsing experience: the producer point of view. Web users are producers of a huge volume of data. This data is being used to analyze our behavioral patterns and extract information. The advertising economic model of the Web is quite simple: create a space to spend time, put some cameras and study user patterns and then sell the placement of the proper content in specific places.
You probably started to notice that advertising follows you, it displays content quite aligned with your day to day and you have probably experimented that sense of being watched when Google seems to know about your forthcoming appointments or travels. If you spend your time in front of a computer you probably use the browser a lot. When you use the browser, you’re navigating safe but the browser can not prevent you for an irresponsible sharing of your privacy. At least, it tries to keep most of your data with you.
Now think about your domestic electronics and personal devices producing and sharing data. This is a lot of data and it is your data. When your connected devices will be talking to the service providers, where will end your information? Will it be shared? Will be possible for a company to manipulate your light bulbs, thermostat, washing machine or TV without your approval? You must demand control, safety and freedom.
As I want to use the Web for interacting with my devices, this is what I want my user agent to become: a regulator for my connected devices. In the same way it is a proxy of my digital life on the Internet, I want my browser to represent my connected environments (my home, my car, me myself…). Why do I want the Web to interface my connected devices? Because the Web is accessible and ubiquitous.
In my ideal future, I can manage my connected environments from any browser, in any platform, at any place (this is freedom), granting and revoking permissions for specific web services to specify the way in which they access my electronics (this is control) and I want the IoT players to push for open solutions, developing a fair game with clear rules and transparent technologies (this allows safety).
Implementing this reality is not a trivial task. How I identify myself as the owner of my connected environments? How can I keep this information safe but accessible from any point? If I switch to a new browser, how could I make this new browser to know about my digital identity? Should the connected devices expose an administration API for my browser to regulate them or they should send the data to some kind of master device which actually manages data traffic?
These questions have answers coming from a range of disciplines and they will require to develop new software and efficient hardware, to design new user experiences, to write new specifications, protocols and standards but moreover, they will demand a joined effort from the several Web companies.
In the same way the World Wide Web emerged from the Internet of Computers, Mainframes and Servers, the Web of Things will emerge from IoT. It is the mission of user agents and the institutions behind them to help the user to keep the ownership of their digital life in this new medium.
I recently discovered PEP 0302 about extending the import machinery so I just published gistimporter as a proof of concept. It allows you to add Gists as locations for your imported modules. The library is already in PyPI and ready to be installed. Any feedback is welcome!
I wrote this quick remap.js plug-in for require.js. Personally, I bundle my JS libraries with UMD but I love require.js for unit testing and with remap.js you can easily rewire your dependencies providing true isolation.
This is an early release and it can be bugged but you’ll get the idea. Enjoy!
This is the second post of a series of articles about how the several technologies conforming the New Gaia Architecture (NGA) fit together to speed the Web.
In the first chapter, we focused on performance and resource efficiency and we realised the potential conflict between the multi-page approach to web applications where each view is isolated in its own (no iframe) document and the need for keeping in memory all the essential logic & data to avoid unnecessary delays and meet the time constrains for an optimal user experience.
In this chapter I will explore web workers in its several flavours: dedicated workers, shared workers and service workers and how they can be combined to beat some of these delays. As a reminder, here is the breakdown from the previous episode:
Navigate to a new document.
Download resources (which includes the template).
Set your environment up (include loading shared libraries).
I spent most part of this year working in Service Workers for the New Gaia Architecture (NGA) that Mozilla is preparing to release with Firefox OS 2.5 & 3.0. This is the first of a series of articles about the effort we are putting in evolving Gaia while contributing to best programming practises for Modern Mobile Web.
More than an architecture, NGA is a set of recommendations to reach specific goals, good not only for Firefox OS applications but for any modern web application: offline availability, resource efficiency, performance and continuity. Different technologies exists (and other are coming) to help reaching each target.
Although, there is some confusion about how all these technologies fit together. Even inside the Firefox OS team some see pinning apps (which is a mechanism to keep and entire site cached forever and it must not to be confused with the concept of pinning the web) overlaps with Offline Cache. Other people see the render store unnecessary and overlapping with the prerender technology. If this is your case or simply you did not know about these concepts, continue reading, you deserve an explanation first.